Gathering data from a webpage with selene¶
Webscraping generally involves a lot of retrieving elements from web pages. In selene, we generally use the PageSelene object as a starting point for element retrieval. The PageSelene object has methods to grab web elements using wrapped selenium and beautiful soup functionality.
[1]:
from selenium.webdriver.common.by import By
from selene.core.logger import get_logger
from selene.core.selenium.driver import get_driver, stop_driver
from selene.core.selenium.page import PageSelene
Starting a session¶
The first thing you need to do to get started is to initialise a selenium webdriver. It is also often good practice to initialise a logger.
[2]:
driver = get_driver(width=800, height=600)
logger = get_logger(level='INFO')
2022-05-16 13:46:00 INFO Logger started
Creating a PageSelene object¶
There are several ways to initialise a PageSelene object (you can check the API for all your options) but one particularly useful one is to create it from a url. The PageSelene object is initialise from a webdriver, url and optional logger.
[3]:
url = 'https://www.scrapethissite.com/pages/simple/'
page = PageSelene.from_url(driver, url, logger=logger)
Our new page object has some helpful functions when working in a notebook, such as this:
[4]:
page.screenshot_to_notebook(driver)
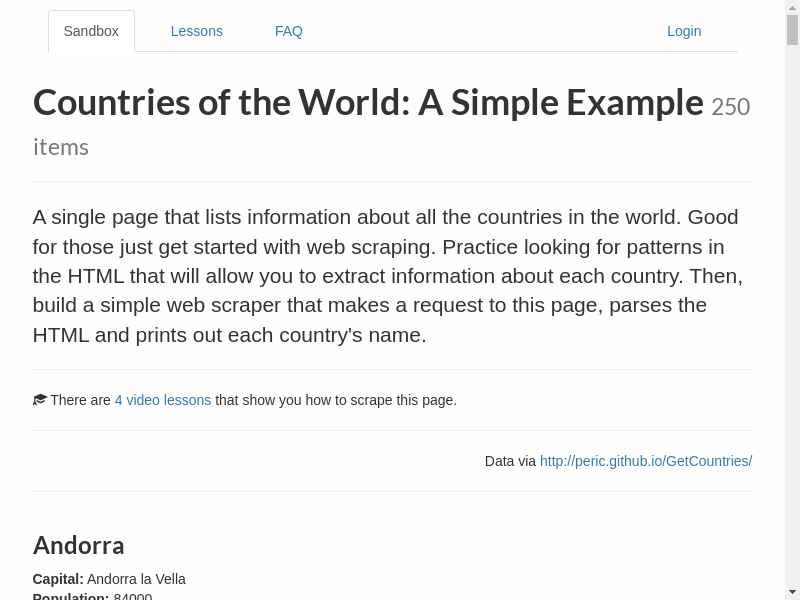
Retrieving elements¶
Element retrieval functionality from a page object in selene comes in 4 varieties: * find - find the first element that meets your criteria using selenium webdriver * find_all - find all elements that meet your criteria using selenium webdriver * find_soup - find the first element that meets your criteria using beautiful soup * find_all_soup - find the first element that meets your criteria using beautiful soup
The selenium webdriver functions return a dynamic element, whereas soup-based functions return a static web element. They can often be used interchangeably. Furthermore, the same find functions can be applied to elements (i.e. ElementSelene) objects as well as to pages, to retrieve sub-elements.
[5]:
page.find(driver, By.TAG_NAME, 'h3').text
[5]:
'Andorra'
Note: elements have a “text” attirbute that will return any text associated with that element. For other attributes associated with elements, you can use the get() method - for example get(“href”) may return a url associated with a web element.
[6]:
for element in page.find_all(driver, By.XPATH, '//*[contains(text(), \'An\')]')[:3]:
print(element.text)
Andorra la Vella
Antananarivo
Ankara
[7]:
page.find_soup('p', {'class': 'lead'}).text
[7]:
"\n A single page that lists information about all the countries in the world. Good for those just get started with web scraping.\n Practice looking for patterns in the HTML that will allow you to extract information about each country. Then, build a simple web scraper that makes a request to this page, parses the HTML and prints out each country's name.\n "
[8]:
for element in page.find_all_soup('span', {'class': 'country-population'})[:3]:
print(element.text)
84000
4975593
29121286
When you’re done, it’s often a good idea to stop the driver:
[9]:
stop_driver(driver)