Building website-specific functionality¶
The real power of selene comes from using it as a starting framework from which to develop website-specific functionality.
Here, we illustrate building website specific functionality for the CMA’s own website:
[1]:
from selenium.webdriver.common.by import By
from selene.core.logger import get_logger
from selene.core.selenium.driver import get_driver, stop_driver
from selene.core.selenium.page import PageSelene
from selene.core.selenium.conditions import *
from selene.core.selenium.crawler import CrawlerSelene
import re
import numpy as np
import pandas as pd
from time import sleep
Defining our new Page objects¶
The starting point for any scraping in selene is the page object. We define two page objects that inherit the general PageSelene class.
These new objects represent types of page on the site. We attach methods to these new objects to carry out certain tasks on those pages, such as closing cookie banners, clicking icons and retrieving elements of interest.
[2]:
class PageCmaCaseList(PageSelene):
""" a class for pages of the form https://www.gov.uk/cma-cases """
def remove_cookie_banner(self, driver):
""" accept cookie banner """
accept_button = self.find(driver, By.XPATH, '//*[@id="global-cookie-message"]/div[1]/div/div[2]/button[1]')
accept_button.click(driver)
def get_case_links(self):
""" retrieve the links to any cases listed on a case list page """
url_regex = re.compile('.*gem-c-document.*govuk-link.*') # note you can use regex to find elements if you need to
link_elements = self.find_all_soup('a', {'class': url_regex})
links = [x.get('href') for x in link_elements]
return links
def click_next_page(self, driver):
""" find the next page button and click on it """
next_page = self.find(driver, By.XPATH, '//*[@id="js-pagination"]/nav/ul/li/a')
next_page.click(driver)
[3]:
class PageCmaCase(PageSelene):
""" a class for the webpage of specific CMA cases, e.g. https://www.gov.uk/cma-cases/vetpartners-limited-slash-goddard-holdco-limited-merger-inquiry """
def get_case_name(self):
""" return the name of the case """
name_text = self.find_soup('h1', {'class': 'gem-c-title__text govuk-heading-l'}).text
if name_text is not None:
name_text = name_text.strip()
return name_text
def get_published_date(self, driver):
""" return published date for case """
date_text = self.find(driver, By.XPATH, '//*[@id="content"]/div[2]/div/div[1]/div/dl/dd[2]').text
if date_text is not None:
date_text = date_text.strip()
return date_text
Crawling the site using our new objects¶
[4]:
driver = get_driver(width=1024, height=768)
logger = get_logger(level='INFO')
url = "http://www.gov.uk/cma-cases"
page = PageCmaCaseList.from_url(driver, url, logger = logger, string="cma-cases") # the string parameter acts as a check that we have navigated to the correct url
2022-06-13 18:38:17 INFO Logger started
[5]:
page.click_next_page(driver)
[6]:
page.screenshot_to_notebook(driver)
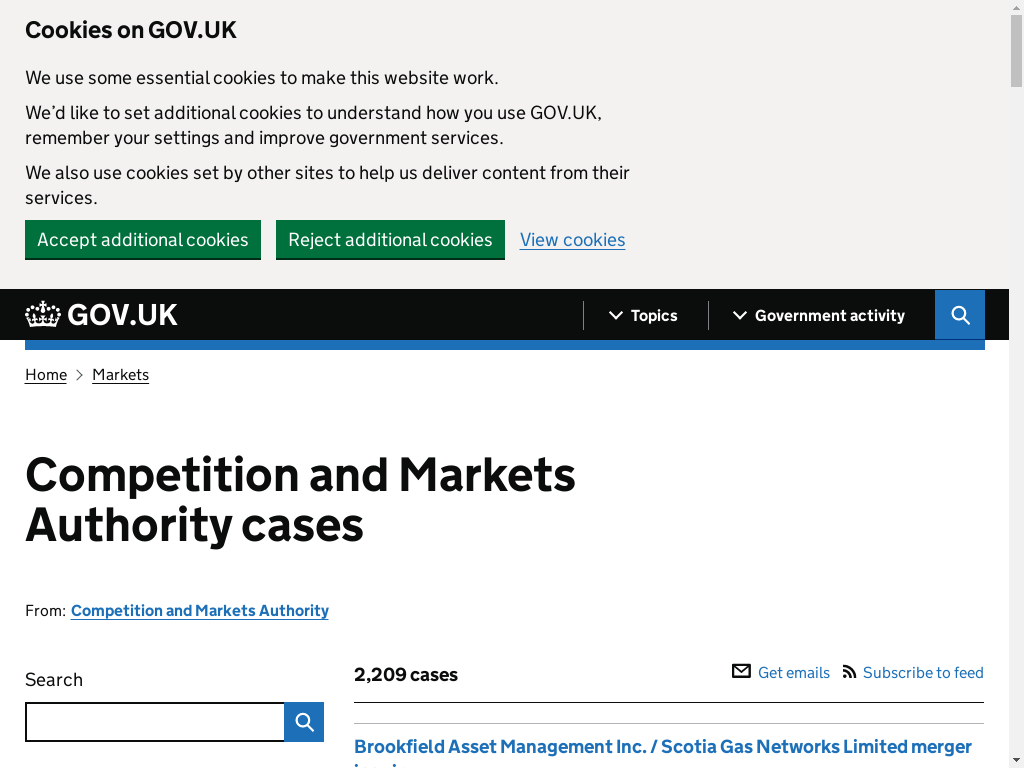
First things first, we need to close the cookie banner.
[7]:
page.remove_cookie_banner(driver)
page.screenshot_to_notebook(driver)
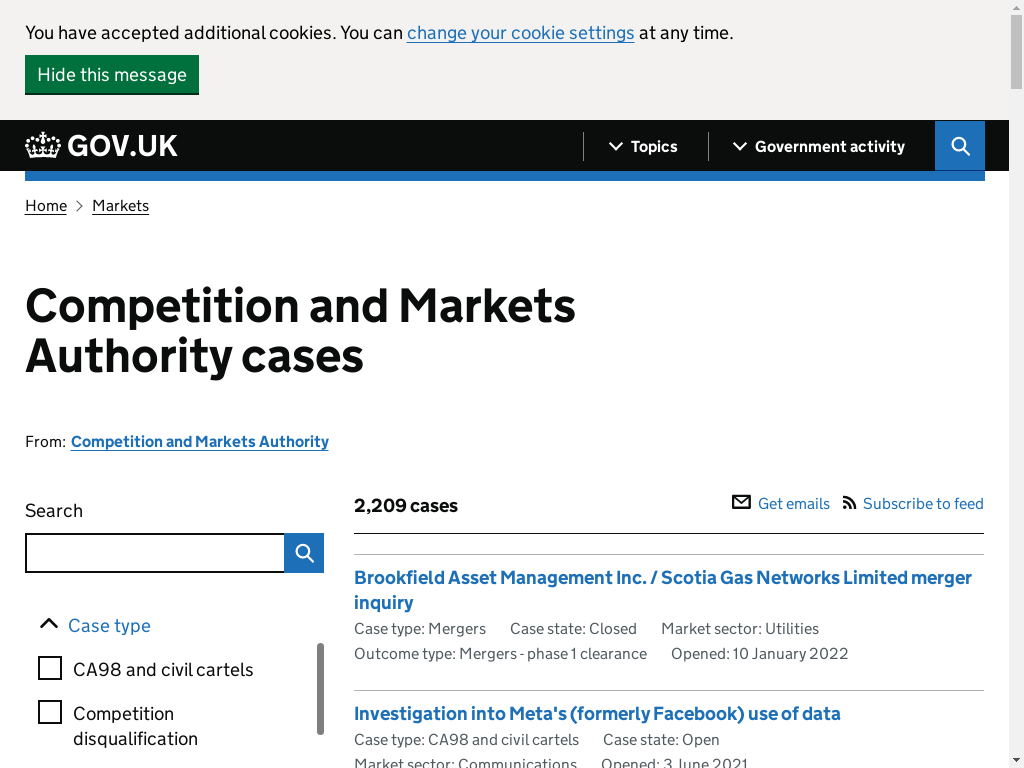
Now, we grab the urls for the individual cases on the first page:
[8]:
urls = page.get_case_links()
urls[:3]
[8]:
['/cma-cases/dye-and-durham-uk-limited-slash-tm-group-uk-limited-merger-inquiry',
'/cma-cases/royalelife-slash-stately-albion-limited-and-slash-or-pathfinder-park-homes-holding-limited-merger-inquiry',
'/cma-cases/ali-holding-srl-slash-welbilt-inc-merger-inquiry']
We visit the first 3 links (using our second PageCmaCase page object) and grab the case name and published date and store this in a pandas dataframe.
[9]:
case_names = []
published_dates = []
for url in urls[:3]:
full_url = f"http://www.gov.uk{url}"
page_case = PageCmaCase.from_url(driver, full_url, logger=None)
case_names.append(page_case.get_case_name())
published_dates.append(page_case.get_published_date(driver))
results = pd.DataFrame({"case": case_names,
"published_date": published_dates})
[10]:
results
[10]:
| case | published_date | |
|---|---|---|
| 0 | Dye & Durham (UK) Limited / TM Group (UK) Limi... | 1 September 2021 |
| 1 | RoyaleLife / Stately-Albion Limited and/or Pat... | 24 March 2022 |
| 2 | Ali Holding S.r.l. / Welbilt, Inc merger inquiry | 10 March 2022 |
Putting it all together¶
Let’s imagine you wanted to collect the case names / published dates for all CMA cases. The workflow might look something like this:
Load first case list page
Generate all urls for inidividual cases
Load these case pages in turn, collating the required information
Click next page
Repeat steps 2 to 4
You can use the selene Crawler class for executing this type of workflow, as in the example below:
[11]:
class CrawlerCma(CrawlerSelene):
""" a crawler object to collect data from the CMA website on cases """
def collect_case_data(self, driver, logger, page_limit, start_url = "http://www.gov.uk/cma-cases"):
""" a function to crawl CMA case lists and collect case names / published dates """
case_names = []
published_dates = []
page_count = 1
page_list = PageCmaCaseList.from_url(driver, start_url, logger = None, string="cma")
while page_count <= page_limit:
page_list.screenshot_to_notebook(driver)
page_urls = page_list.get_case_links()
current_handle = driver.window_handles[0]
for url in page_urls[:5]: # just getting the first 5 links to save some time!
full_url = f"http://www.gov.uk{url}"
sleep(np.random.uniform(low=1, high=5)) # out of politeness
page_case = PageCmaCase.new_tab(driver, full_url, logger=logger)
case_names.append(page_case.get_case_name())
published_dates.append(page_case.get_published_date(driver))
page_case.close_all_tabs_except_specified_tab(driver, handle_keep=current_handle)
self.log(f'Number of tabs open: {len(driver.window_handles)}')
page_list.click_next_page(driver)
page_count += 1
page_list = PageCmaCaseList.from_url(driver, driver.current_url, logger=logger, string="cma")
results = pd.DataFrame({"case": case_names,
"published_date": published_dates})
return results
Let’s see it in action:
[12]:
crawler = CrawlerCma()
output = crawler.collect_case_data(driver=driver, logger=None, page_limit=2)
2022-06-13 18:38:50 INFO Logger started
2022-06-13 18:39:12 DEBUG Crawler: Number of tabs open: 1
2022-06-13 18:39:36 DEBUG Crawler: Number of tabs open: 1
2022-06-13 18:40:00 DEBUG Crawler: Number of tabs open: 1
2022-06-13 18:40:24 DEBUG Crawler: Number of tabs open: 1
2022-06-13 18:40:49 DEBUG Crawler: Number of tabs open: 1
2022-06-13 18:41:14 DEBUG Crawler: Number of tabs open: 1
2022-06-13 18:41:37 DEBUG Crawler: Number of tabs open: 1
2022-06-13 18:42:03 DEBUG Crawler: Number of tabs open: 1
2022-06-13 18:42:29 DEBUG Crawler: Number of tabs open: 1
2022-06-13 18:42:54 DEBUG Crawler: Number of tabs open: 1
[13]:
output
[13]:
| case | published_date | |
|---|---|---|
| 0 | Dye & Durham (UK) Limited / TM Group (UK) Limi... | 1 September 2021 |
| 1 | RoyaleLife / Stately-Albion Limited and/or Pat... | 24 March 2022 |
| 2 | Ali Holding S.r.l. / Welbilt, Inc merger inquiry | 10 March 2022 |
| 3 | UK fuel retail market review | 13 June 2022 |
| 4 | Investigation into a capacity sharing agreemen... | 12 November 2021 |
| 5 | Brookfield Asset Management Inc. / Scotia Gas ... | 11 January 2022 |
| 6 | Investigation into Meta's (formerly Facebook) ... | 4 June 2021 |
| 7 | Self-funded IVF: consumer law guidance | 7 February 2020 |
| 8 | Financial services sector: suspected anti-comp... | 16 November 2018 |
| 9 | Huws Gray Ltd / Grafton Plc | 11 October 2021 |
This code could be written outside of selene, but sometimes it’s helpful to retain useful code within the selene framework so it can be re-used in future.
[14]:
stop_driver(driver)